[nltk Books] Chapter 2. Accessing Text Corpora and Lexical Resources
Author : tmlab / Date : 2016. 10. 27. 17:55 / Category : Text Mining/Python
In [1]:
import nltk
In [2]:
from nltk.corpus import gutenberg
gutenberg.fileids()
Out[2]:
In [3]:
emma = gutenberg.words("austen-emma.txt")
len(emma)
Out[3]:
In [4]:
print(gutenberg.raw("austen-emma.txt")[:1000])
In [5]:
emma1 = nltk.Text(emma)
emma1.concordance("surprize")
In [6]:
for fileid in gutenberg.fileids():
num_chars = len(gutenberg.raw(fileid))
num_words = len(gutenberg.words(fileid))
num_sents = len(gutenberg.sents(fileid))
num_vocab = len(set(w.lower() for w in gutenberg.words(fileid)))
print(round(num_chars/num_words),round(num_words/num_sents),round(num_words/num_vocab),fileid)
In [7]:
macbeth_sentences = gutenberg.sents("shakespeare-macbeth.txt")
print(macbeth_sentences,"\n")
print(macbeth_sentences[1116],"\n")
longest_len = max(len(s) for s in macbeth_sentences)
print([s for s in macbeth_sentences if len(s) == longest_len])
In [8]:
from nltk.corpus import webtext as web
print(web.fileids(),"\n\n")
for fileid in web.fileids():
print(fileid, web.raw(fileid)[:65],"\n")
In [9]:
from nltk.corpus import nps_chat as chat
print("FILE: ",chat.fileids(),"\n")
chatroom = chat.posts('10-19-20s_706posts.xml')
print("예제: ",chatroom[123])
In [10]:
from nltk.corpus import brown
print(brown.categories(),"\n")
print(brown.words(categories="news"),"\n")
print(brown.words(fileids=['cg22']),"\n")
print(brown.sents(categories=["news","editorial","reviews"]))
In [11]:
news_text = brown.words(categories="news")
fdist = nltk.FreqDist(w.lower() for w in news_text)
modals = ["can","could","may","might","must","will"]
for m in modals:
print(m+":",fdist[m],end = " ")
In [12]:
cfd = nltk.ConditionalFreqDist(
(genre, word)
for genre in brown.categories()
for word in brown.words(categories = genre))
genres = ["news","religion","hobbies","science_fiction","romance","humor"]
cfd.tabulate(conditions=genres,samples=modals)
In [13]:
from nltk.corpus import reuters as rt
print(rt.fileids()[:6],"\n")
print(rt.categories())
In [14]:
print(rt.categories('training/9865'),"\n")
print(rt.categories('training/9880'),"\n")
print(rt.fileids("barley"),"\n")
In [15]:
print(rt.words("training/9865")[:14])
In [16]:
import matplotlib.pyplot as plt
%matplotlib nbagg
In [17]:
>>> from nltk.corpus import inaugural
>>> print(inaugural.fileids(),"\n")
>>> print([fileid[:4] for fileid in inaugural.fileids()])
In [18]:
>>> cfd = nltk.ConditionalFreqDist(
... (target, fileid[:4])
... for fileid in inaugural.fileids()
... for w in inaugural.words(fileid)
... for target in ['america', 'citizen']
... if w.lower().startswith(target))
>>> cfd.plot()

In [19]:
print(nltk.corpus.cess_esp.words(),"\n")
print(nltk.corpus.floresta.words(),"\n")
print(nltk.corpus.indian.words('hindi.pos'),"\n")
print(nltk.corpus.udhr.fileids()[:10],"\n")
print(nltk.corpus.udhr.words("Korean_Hankuko-UTF8")[:14],"\n")
print(nltk.corpus.udhr.words('Javanese-Latin1')[11:],"\n")
In [20]:
>>> from nltk.corpus import udhr
>>> languages = ['Chickasaw', 'English', 'German_Deutsch',
... 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
>>> cfd = nltk.ConditionalFreqDist(
... (lang, len(word))
... for lang in languages
... for word in udhr.words(lang + '-Latin1'))
>>> cfd.plot(cumulative=True)

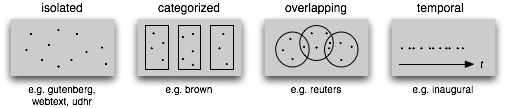
In [21]:
from nltk.corpus import PlaintextCorpusReader as pcr
corpus_root = "./"
wordlists = pcr(corpus_root,".*")
In [22]:
print(wordlists.fileids(),"\n")
print(wordlists.words("thesis.txt"))
In [23]:
wordlists.sents()
Out[23]:
In [ ]:
>>> from nltk.corpus import BracketParseCorpusReader
>>> corpus_root = r"C:\corpora\penntreebank\parsed\mrg\wsj"
>>> file_pattern = r".*/wsj_.*\.mrg"
>>> ptb = BracketParseCorpusReader(corpus_root, file_pattern)
>>> ptb.fileids()
['00/wsj_0001.mrg', '00/wsj_0002.mrg', '00/wsj_0003.mrg', '00/wsj_0004.mrg', ...]
>>> len(ptb.sents())
49208
>>> ptb.sents(fileids='20/wsj_2013.mrg')[19]
['The', '55-year-old', 'Mr.', 'Noriega', 'is', "n't", 'as', 'smooth', 'as', 'the',
'shah', 'of', 'Iran', ',', 'as', 'well-born', 'as', 'Nicaragua', "'s", 'Anastasio',
'Somoza', ',', 'as', 'imperial', 'as', 'Ferdinand', 'Marcos', 'of', 'the', 'Philippines',
'or', 'as', 'bloody', 'as', 'Haiti', "'s", 'Baby', Doc', 'Duvalier', '.']
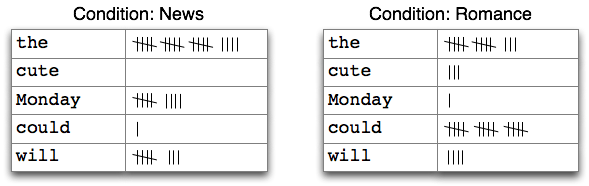
In [24]:
>>> from nltk.corpus import brown
>>> cfd = nltk.ConditionalFreqDist(
... (genre, word)
... for genre in brown.categories()
... for word in brown.words(categories=genre))
In [25]:
genre_word = [(genre,word)
for genre in ["news","romance"]
for word in brown.words(categories=genre)]
len(genre_word)
Out[25]:
In [26]:
print(genre_word[:4],"\n")
print(genre_word[-4:])
In [27]:
cfd = nltk.ConditionalFreqDist(genre_word)
print(cfd)
print(cfd.conditions())
In [28]:
print(cfd["news"])
print(cfd["romance"])
print(cfd["romance"].most_common(10))
In [29]:
>>> from nltk.corpus import inaugural
>>> cfd = nltk.ConditionalFreqDist(
... (target, fileid[:4])
... for fileid in inaugural.fileids()
... for w in inaugural.words(fileid)
... for target in ['america', 'citizen']
... if w.lower().startswith(target))
In [30]:
>>> from nltk.corpus import udhr
>>> languages = ['Chickasaw', 'English', 'German_Deutsch',
... 'Greenlandic_Inuktikut', 'Hungarian_Magyar', 'Ibibio_Efik']
>>> cfd = nltk.ConditionalFreqDist(
... (lang, len(word))
... for lang in languages
... for word in udhr.words(lang + '-Latin1'))
In [31]:
>>> cfd.tabulate(conditions=['English', 'German_Deutsch'],
... samples=range(10), cumulative=True)
In [32]:
from nltk.util import bigrams
>>> sent = ['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven',
... 'and', 'the', 'earth', '.']
>>> list(nltk.bigrams(sent))
Out[32]:
In [33]:
def generate_model(cfdist, word, num=15):
for i in range(num):
print(word, end=' ')
word = cfdist[word].max()
text = nltk.corpus.genesis.words('english-kjv.txt')
bigrams = nltk.bigrams(text)
cfd = nltk.ConditionalFreqDist(bigrams)
In [34]:
cfd["living"]
Out[34]:
In [35]:
generate_model(cfd,"living")
In [36]:
>>> def lexical_diversity(my_text_data):
... word_count = len(my_text_data)
... vocab_size = len(set(my_text_data))
... diversity_score = vocab_size / word_count
... return diversity_score
In [37]:
>>> from nltk.corpus import genesis
>>> kjv = genesis.words('english-kjv.txt')
>>> lexical_diversity(kjv)
Out[37]:

In [38]:
def unusual_words(text):
text_vocab = set(w.lower() for w in text if w.isalpha())
english_vocab = set(w.lower() for w in nltk.corpus.words.words())
unusual = text_vocab - english_vocab
return sorted(unusual)
In [39]:
print(unusual_words(nltk.corpus.gutenberg.words("austen-sense.txt"))[:6])
In [40]:
from nltk.corpus import stopwords
print(stopwords.words("english"))
In [41]:
>>> def content_fraction(text):
... stopwords = nltk.corpus.stopwords.words('english')
... content = [w for w in text if w.lower() not in stopwords]
... return len(content) / len(text)
...
>>> content_fraction(nltk.corpus.reuters.words())
Out[41]:
In [42]:
>>> entries = nltk.corpus.cmudict.entries()
>>> len(entries)
Out[42]:
In [43]:
>>> for entry in entries[42371:42379]:
... print(entry)
In [44]:
from nltk.corpus import swadesh
print(swadesh.fileids(),"\n")
print(swadesh.words("en"))
In [45]:
>>> fr2en = swadesh.entries(['fr', 'en'])
>>> print(fr2en[:6],"\n")
>>> translate = dict(fr2en)
>>> print(translate['chien'],"\n")
>>> print(translate['jeter'])
In [47]:
>>> from nltk.corpus import toolbox
>>> toolbox.entries('rotokas.dic')[:2]
Out[47]:
In [48]:
>>> from nltk.corpus import wordnet as wn
>>> wn.synsets('motorcar')
Out[48]:
In [49]:
>>> wn.synset('car.n.01').lemma_names()
Out[49]:
In [50]:
>>> print(wn.synset('car.n.01').definition(),"\n")
>>> print(wn.synset('car.n.01').examples())
In [51]:
print(wn.synset('car.n.01').lemmas(),"\n")
print(wn.lemma('car.n.01.automobile'),"\n")
print(wn.lemma('car.n.01.automobile').synset(),"\n")
print(wn.lemma('car.n.01.automobile').name())
In [52]:
print(wn.synsets("car"),"\n")
>>> for synset in wn.synsets('car'):
... print(synset.lemma_names())
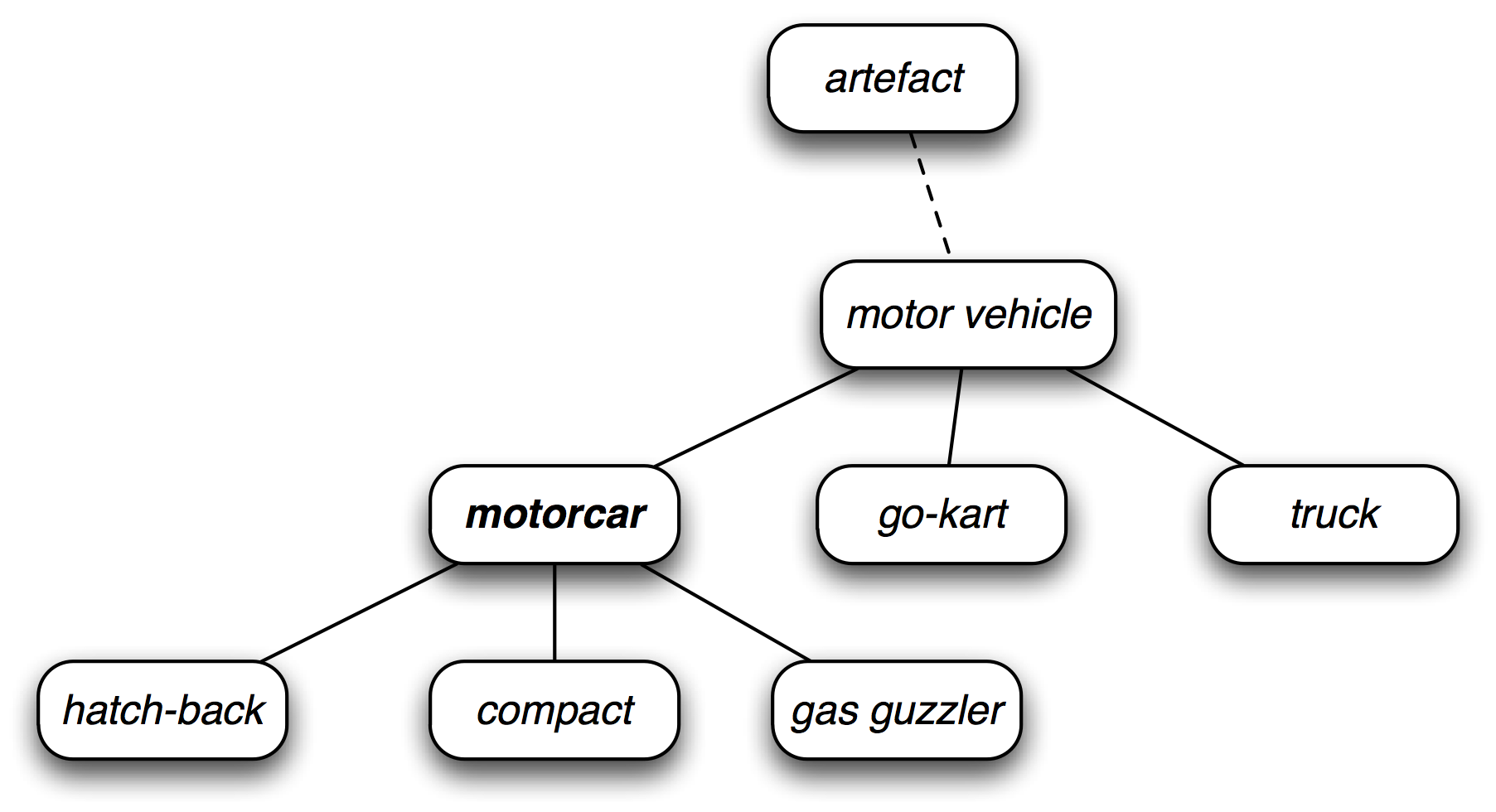
In [55]:
motorcar = wn.synset('car.n.01')
types_of_motorcar = motorcar.hyponyms()
sorted(lemma.name() for synset in types_of_motorcar for lemma in synset.lemmas())
Out[55]:
In [56]:
print(motorcar.hypernyms(),"\n")
paths = motorcar.hypernym_paths()
print(len(paths),"\n")
print([synset.name() for synset in paths[0]],"\n")
print([synset.name() for synset in paths[1]],"\n")
In [57]:
>>> motorcar.root_hypernyms()
Out[57]:
In [58]:
print(wn.synset('tree.n.01').part_meronyms(),"\n")
print(wn.synset('tree.n.01').substance_meronyms(),"\n")
print(wn.synset('tree.n.01').member_holonyms())
In [59]:
>>> for synset in wn.synsets('mint', wn.NOUN):
... print(synset.name() + ':', synset.definition())
In [60]:
print(wn.synset('mint.n.04').part_holonyms(),"\n")
print(wn.synset('mint.n.04').substance_holonyms())
In [61]:
>>> print(wn.synset('walk.v.01').entailments(),"\n")
>>> print(wn.synset('eat.v.01').entailments(),"\n")
>>> print(wn.synset('tease.v.03').entailments(),"\n")
In [62]:
>>> print(wn.lemma('supply.n.02.supply').antonyms(),"\n")
>>> print(wn.lemma('rush.v.01.rush').antonyms(),"\n")
>>> print(wn.lemma('horizontal.a.01.horizontal').antonyms(),"\n")
>>> print(wn.lemma('staccato.r.01.staccato').antonyms(),"\n")
In [63]:
>>> right = wn.synset('right_whale.n.01')
>>> orca = wn.synset('orca.n.01')
>>> minke = wn.synset('minke_whale.n.01')
>>> tortoise = wn.synset('tortoise.n.01')
>>> novel = wn.synset('novel.n.01')
In [64]:
print(right.lowest_common_hypernyms(minke),"\n")
print(right.lowest_common_hypernyms(orca),"\n")
print(right.lowest_common_hypernyms(tortoise),"\n")
print(right.lowest_common_hypernyms(novel))
In [65]:
>>> print(wn.synset('baleen_whale.n.01').min_depth(),"\n")
>>> print(wn.synset('whale.n.02').min_depth(),"\n")
>>> print(wn.synset('vertebrate.n.01').min_depth(),"\n")
>>> print(wn.synset('entity.n.01').min_depth())
In [66]:
>>> right.path_similarity(minke)
Out[66]:
In [67]:
>>> right.path_similarity(orca)
Out[67]:
In [68]:
>>> right.path_similarity(tortoise)
Out[68]:
In [69]:
>>> right.path_similarity(novel)
Out[69]: