[nltk Books] Chapter 5. Categorizing and Tagging Words
Author : tmlab / Date : 2016. 10. 27. 17:56 / Category : Text Mining/Python
In [1]:
import nltk, re, pprint
from nltk import word_tokenize
In [2]:
text = word_tokenize("And now for something completely different")
nltk.pos_tag(text)
Out[2]:
In [3]:
text = word_tokenize("They refuse to permit us to obtain the refuse permit")
nltk.pos_tag(text)
Out[3]:
In [4]:
text = nltk.Text(word.lower() for word in nltk.corpus.brown.words()) #소문자로 변경
text.similar('woman')
In [5]:
text.similar('bought')
In [6]:
text.similar('over')
In [7]:
text.similar('the')
In [8]:
tagged_token = nltk.tag.str2tuple('fly/NN')
tagged_token
Out[8]:
In [9]:
sent = '''The/AT grand/JJ jury/NN commented/VBD on/IN a/AT number/NN of/IN
other/AP topics/NNS ,/, AMONG/IN them/PPO the/AT Atlanta/NP and/CC
Fulton/NP-tl County/NN-tl purchasing/VBG departments/NNS which/WDT it/PPS
said/VBD ``/`` ARE/BER well/QL operated/VBN and/CC follow/VB generally/RB
accepted/VBN practices/NNS which/WDT inure/VB to/IN the/AT best/JJT
interest/NN of/IN both/ABX governments/NNS ''/'' ./.'''
In [10]:
[nltk.tag.str2tuple(t) for t in sent.split()]
Out[10]:
In [11]:
nltk.corpus.brown.tagged_words()
Out[11]:
In [12]:
nltk.corpus.brown.tagged_words(tagset='universal')
Out[12]:
In [13]:
print(nltk.corpus.nps_chat.tagged_words())
In [14]:
nltk.corpus.conll2000.tagged_words()
Out[14]:
In [15]:
nltk.corpus.treebank.tagged_words()
Out[15]:
In [16]:
nltk.corpus.brown.tagged_words(tagset='universal')
Out[16]:
In [17]:
nltk.corpus.treebank.tagged_words(tagset='universal')
Out[17]:
In [18]:
from nltk.corpus import brown
brown_news_tagged = brown.tagged_words(categories='news', tagset='universal')
tag_fd = nltk.FreqDist(tag for (word, tag) in brown_news_tagged)
tag_fd.most_common()
Out[18]:
In [19]:
word_tag_pairs = nltk.bigrams(brown_news_tagged)
noun_preceders = [a[1] for (a, b) in word_tag_pairs if b[1] == 'NOUN']
fdist = nltk.FreqDist(noun_preceders)
[tag for (tag, _) in fdist.most_common()]
Out[19]:
In [20]:
def findtags(tag_prefix, tagged_text):
cfd = nltk.ConditionalFreqDist((tag, word) for (word, tag) in tagged_text
if tag.startswith(tag_prefix))
return dict((tag, cfd[tag].most_common(5)) for tag in cfd.conditions())
In [21]:
tagdict = findtags('NN', nltk.corpus.brown.tagged_words(categories='news'))
for tag in sorted(tagdict):
print(tag, tagdict[tag])
In [22]:
brown_lrnd_tagged = brown.tagged_words(categories='learned', tagset='universal')
tags = [b[1] for (a, b) in nltk.bigrams(brown_lrnd_tagged) if a[0] == 'often']
fd = nltk.FreqDist(tags)
fd.tabulate()
In [23]:
from nltk.corpus import brown
brown_tagged_sents = brown.tagged_sents(categories='news')
brown_sents = brown.sents(categories='news')
In [24]:
tags = [tag for (word, tag) in brown.tagged_words(categories='news')]
nltk.FreqDist(tags).max()
Out[24]:
In [25]:
raw = 'I do not like green eggs and ham, I do not like them Sam I am!'
tokens = word_tokenize(raw)
default_tagger = nltk.DefaultTagger('NN')
default_tagger.tag(tokens)
Out[25]:
In [26]:
default_tagger.evaluate(brown_tagged_sents)
Out[26]:
In [27]:
patterns = [
(r'.*ing$', 'VBG'), # gerunds
(r'.*ed$', 'VBD'), # simple past
(r'.*es$', 'VBZ'), # 3rd singular present
(r'.*ould$', 'MD'), # modals
(r'.*\'s$', 'NN$'), # possessive nouns
(r'.*s$', 'NNS'), # plural nouns
(r'^-?[0-9]+(.[0-9]+)?$', 'CD'), # cardinal numbers
(r'.*', 'NN') # nouns (default)
]
In [28]:
regexp_tagger = nltk.RegexpTagger(patterns)
regexp_tagger.tag(brown_sents[3])
Out[28]:
In [29]:
regexp_tagger.evaluate(brown_tagged_sents)
Out[29]:
In [30]:
fd = nltk.FreqDist(brown.words(categories='news')) #브라운코퍼스 빈출워드
cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news')) #태그된 단어들의 조건부 빈도
most_freq_words = fd.most_common(100) #제일 많이 나온 단어 100
likely_tags = dict((word, cfd[word].max()) for (word, _) in most_freq_words) #많이 나온 단어 100의 POS
baseline_tagger = nltk.UnigramTagger(model=likely_tags) #100개에서 추출한
baseline_tagger.evaluate(brown_tagged_sents)
Out[30]:
In [31]:
sent = brown.sents(categories='news')[3]
baseline_tagger.tag(sent)
Out[31]:
In [34]:
baseline_tagger = nltk.UnigramTagger(model=likely_tags,
backoff=nltk.DefaultTagger('NN'))
baseline_tagger.evaluate(brown_tagged_sents)
Out[34]:
In [35]:
sent = brown.sents(categories='news')[3]
baseline_tagger.tag(sent)
Out[35]:
In [36]:
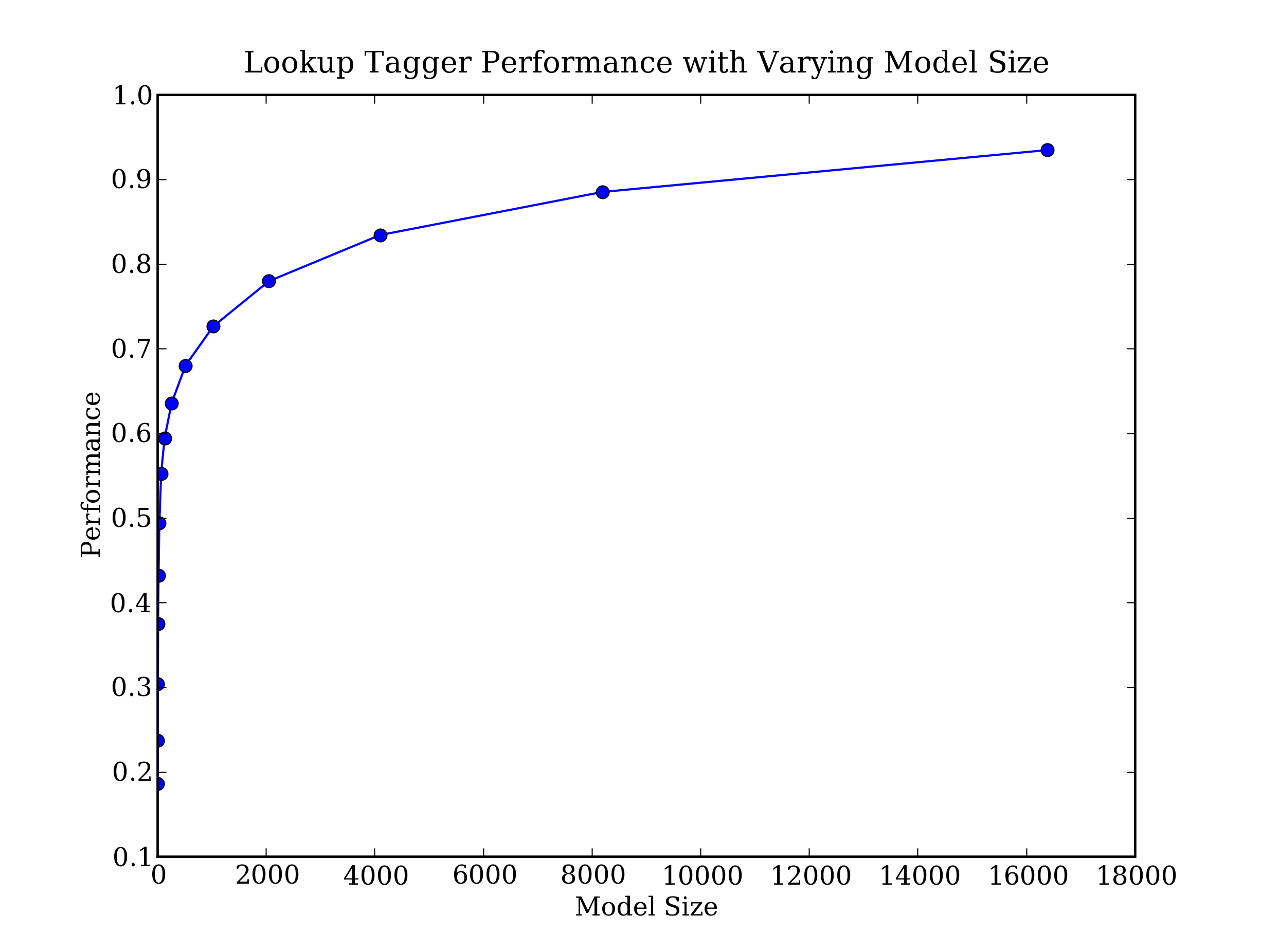
def performance(cfd, wordlist):
lt = dict((word, cfd[word].max()) for word in wordlist)
baseline_tagger = nltk.UnigramTagger(model=lt, backoff=nltk.DefaultTagger('NN'))
return baseline_tagger.evaluate(brown.tagged_sents(categories='news'))
def display():
import pylab
word_freqs = nltk.FreqDist(brown.words(categories='news')).most_common()
words_by_freq = [w for (w, _) in word_freqs]
cfd = nltk.ConditionalFreqDist(brown.tagged_words(categories='news'))
sizes = 2 ** pylab.arange(15)
perfs = [performance(cfd, words_by_freq[:size]) for size in sizes]
pylab.plot(sizes, perfs, '-bo')
pylab.title('Lookup Tagger Performance with Varying Model Size')
pylab.xlabel('Model Size')
pylab.ylabel('Performance')
pylab.show()
In [38]:
from nltk.corpus import brown
brown_tagged_sents = brown.tagged_sents(categories='news')
brown_sents = brown.sents(categories='news')
unigram_tagger = nltk.UnigramTagger(brown_tagged_sents)
unigram_tagger.tag(brown_sents[2007])
Out[38]:
In [39]:
unigram_tagger.evaluate(brown_tagged_sents)
Out[39]:
In [41]:
size = int(len(brown_tagged_sents) * 0.9)
size
Out[41]:
In [42]:
train_sents = brown_tagged_sents[:size]
test_sents = brown_tagged_sents[size:]
unigram_tagger = nltk.UnigramTagger(train_sents)
unigram_tagger.evaluate(test_sents)
Out[42]:
In [44]:
bigram_tagger = nltk.BigramTagger(train_sents)
bigram_tagger.tag(brown_sents[2007])
Out[44]:
In [45]:
unseen_sent = brown_sents[4203]
bigram_tagger.tag(unseen_sent)
Out[45]:
In [46]:
bigram_tagger.evaluate(test_sents)
Out[46]:
In [47]:
t0 = nltk.DefaultTagger('NN') #다 명사로 붙임
t1 = nltk.UnigramTagger(train_sents, backoff=t0) #유니그램 태거
t2 = nltk.BigramTagger(train_sents, backoff=t1) #바이그램 태거
t2.evaluate(test_sents)
Out[47]:
In [48]:
# 저장
from pickle import dump
output = open('t2.pkl', 'wb')
dump(t2, output, -1)
output.close()
In [49]:
# 로드
from pickle import load
input = open('t2.pkl', 'rb')
tagger = load(input)
input.close()
In [50]:
text = """The board's action shows what free enterprise is up against in our complex maze of regulatory laws ."""
tokens = text.split()
tagger.tag(tokens)
Out[50]:
In [ ]:
nltk.tag.brill.demo()